Managed Synchrony with Confluence Data Center - Using Official Atlassian Chart and Image
Doing the unstuck. Atlassian marketing recommends using managed synchrony for datacenter deployments for its simpler setup, with less ongoing maintenance. On the other hand, Atlassian helm chart devs turned down feature reqests asking for support of managed synchrony in the official helm chart claiming issues with platform support and 2 separate JVM processes is not good practice in Kubernetes.
Of course, my client was asking for exactly that, i.e. porting the existing Confluence server with managed synchrony deployment driven by ahem… my chart and uhm… my image (this was all created when Atlassian was not providing either) to datacenter. That took me some time to figure out. See end of this post for the twists and turns. Anyway, with my chart and image combo I had full control to test without the restrictions imposed by the official pair. Next step was to prove the concept with unmodified Atlassian chart and image. But let’s take it step by step. First things first:
DISCLAIMER: Just because you can do it does not mean you should do it. There is no warranty for this setup being safe, let alone production ready. Any critical failures, data loss, screaming users, dead kittens are yours to keep. This page is meant as a proof of concept only. If in doubt, ask Atlassian support.
Teaser
# confluence-1 container log
logClusterMembers Cluster now has 2 members: [[10.42.0.14]:5801, [10.42.0.15]:5801]
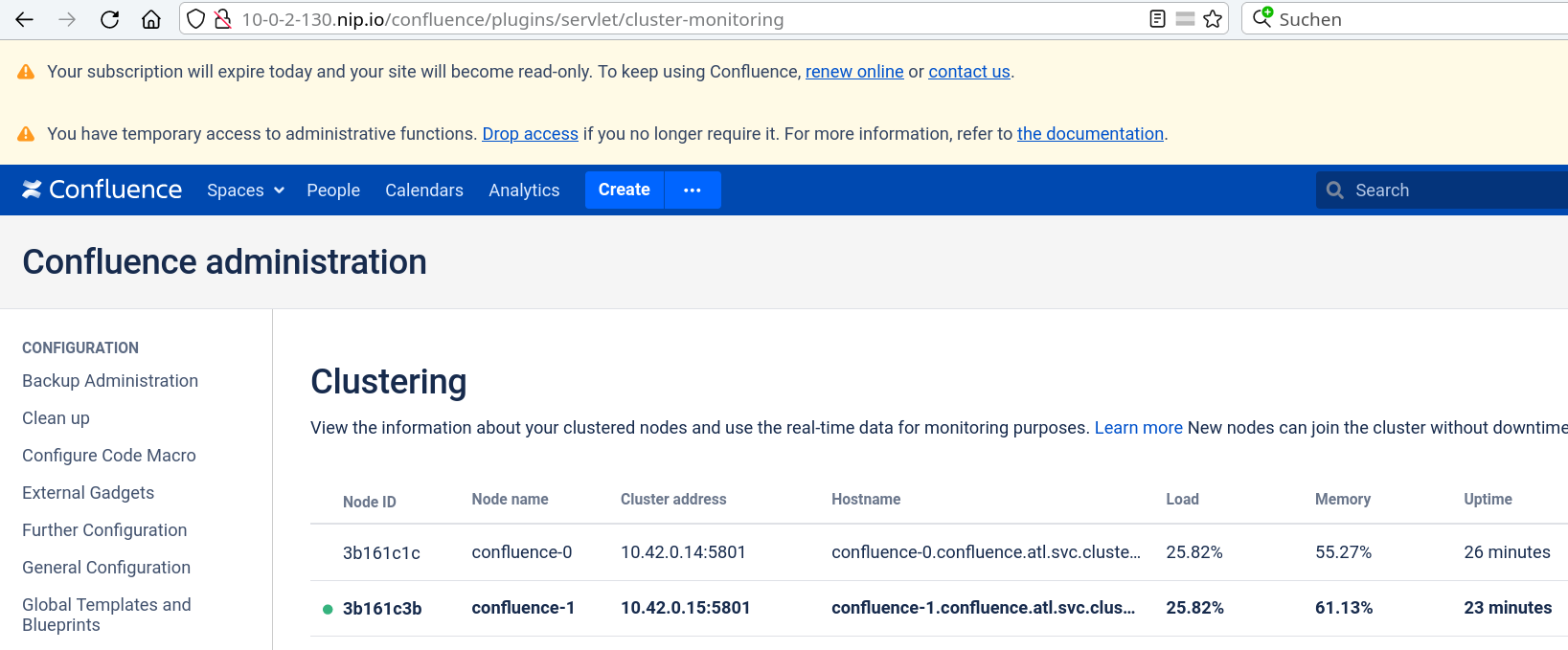

# cat logs/atlassian-synchrony.log
Members {size:2, ver:2} [
Member [10.42.0.14]:5701 - 2f1234c5-c404-48f4-b1cf-b5d3addabbf4
Member [10.42.0.15]:5701 - 15b9d0a3-1b6c-48bd-96ee-bb6375eb7052 this
]

Test Setup
If you already have a kubernetes cluster and want to dive right into it, check my chart overrides, Happy Helming!
I prefer a completely fresh playground for testing
- a single container Rancher “cluster” with istio
- clone of the Atlassian helm charts
- if you are helm deploying from source checkout, copy the common chart into
confluence/charts/. - helm and kubectl binaries with kubeconfig fetched from Rancher
In the Rancher cluster
- create a namespace atl
- deploy a postgresql server
- optionally deploy istio gateway, virtualservice, destination rule
- create a hostpath pv and pvc to mount as shared-home into the confluence pods
Overrides
Atlassian may not support the setup but with a few tricks in overrides one can bend the chart to do it. In summary, we need
- additional ports on the pod
- env override to disable the disabling of managed synchrony
- additional configmap to put synchrony properties into synchrony-args.properties
I will explain the relevant parts of the diff -uw values.yaml overrides.yaml. Chart and image version here is 8.5.0. The full overrides file is here. Again, be warned that this is a testing configuration. In my overrides, all security things are disabled.
@@ -280,9 +280,9 @@
# https://kubernetes.io/docs/concepts/storage/persistent-volumes/#static
# https://atlassian.github.io/data-center-helm-charts/examples/storage/aws/SHARED_STORAGE/
#
- customVolume: {}
- # persistentVolumeClaim:
- # claimName: "<pvc>"
+ customVolume:
+ persistentVolumeClaim:
+ claimName: "confluence"
# -- Specifies the path in the Confluence container to which the shared-home volume will be
# mounted.Shared home pvc. In Rancher, just go to Storage and create a pv of hostpath type. Then deploy a pvc/confluence to atl namespace. Nevermind it being marked as RWO.
@@ -569,7 +569,7 @@
# -- The port on which the Confluence container listens for Hazelcast traffic
#
- hazelcast: 5701
+ hazelcast: 5801
# Confluence licensing details
#I set confluence back to its default hazelcast port. Which means the upstream hazelcast default is free for synchrony to use. It would also be possible to do it the other way around, like having confluence on 5701 and synchrony on 5801. But that would make the confusion complete because when, for lack of a kubernetes cluster, you try to test with a plain docker stack, confluence would come up on port 5801 and synchrony on 5701. So let’s configure this the same here.
@@ -696,7 +696,7 @@
# -- Set to 'true' if Data Center clustering should be enabled
# This will automatically configure cluster peer discovery between cluster nodes.
#
- enabled: false
+ enabled: true
# -- Set to 'true' if the K8s pod name should be used as the end-user-visible
# name of the Data Center cluster node.
@@ -793,7 +793,7 @@
# By default, confluence.cfg.xml is generated only once. Set `forceConfigUpdate` to true
# to change this behavior.
#
- forceConfigUpdate: false
+ forceConfigUpdate: true
# -- Specifies a list of additional arguments that can be passed to the Confluence JVM, e.g.
# system properties.Sure I want datacenter and, yes, I want the entrypoint to replace confluence.cfg.xml on disk. These testing overrides use emptyDir for local-home anyway.
@@ -890,14 +890,27 @@
# container. See https://hub.docker.com/r/atlassian/confluence-server for
# supported variables.
#
- additionalEnvironmentVariables: []
+ additionalEnvironmentVariables:
+ - name: JVM_SUPPORT_RECOMMENDED_ARGS
+ value: -Dconfluence.clusterNodeName.useHostname=true -Dhazelcast.kubernetes.service-port=5801 -Dsynchrony.proxy.enabled=true
+ - name: ATL_JDBC_USER
+ value: confluence
+ - name: ATL_JDBC_PASSWORD
+ value: confluence
+ - name: ATL_LICENSE_KEY
+ value: <timebomb license>
# -- Defines any additional ports for the Confluence container.
#
- additionalPorts: []
- # - name: jmx
- # containerPort: 5555
- # protocol: TCP
+ additionalPorts:
+ - name: hazelsynchrony
+ containerPort: 5701
+ protocol: TCP
+ - name: hazelaleph
+ containerPort: 25500
+ protocol: TCP
# -- Defines additional volumeClaimTemplates that should be applied to the Confluence pod.
# Note that this will not create any corresponding volume mounts;Here is where the fun starts. Atlassian devs actually hardcoded properties to disable synchrony in datacenter mode. See chart _helpers.tpl. Those properties then go to a configmap which then ends up being sourced into a container env JVM_SUPPORT_RECOMMENDED_ARGS in the pod template. Luckily, additional envs defined in the overrides file get templated into a position after the generated ones. So I can just override the blocking configmap based env with a duplicated env name. The first property is also in the configmap, the second is somewhat redundantly (because of the container env HAZELCAST_KUBERNETES_SERVICE_PORT) telling the hazelcast kubernetes plugin the service port which is important because it also applies to the remote ports hazelcast is scanning, the third property enables the manged synchrony-proxy. Instead of overriding the JVM_SUPPORT env I could just as well have set CATALINA_OPTS with the prop keys and different values. Works as long as my props come after the generated props. Last one wins.
Next is podspec container ports. I also added the aleph port, though I have no idea what that is used for. Note that those ports do not have to be listed in the svc manifest. Hazelcast works between hosts (=pods) and only requires the svc name to get pod ip from the endpoints attached to the service.
@@ -1375,15 +1388,15 @@
# -- Create additional ConfigMaps with given names, keys and content. Ther Helm release name will be used as a prefix
# for a ConfigMap name, fileName is used as subPath
#
-additionalConfigMaps: []
-# - name: extra-configmap
-# keys:
-# - fileName: hello.properties
-# mountPath: /opt/atlassian/jira/atlassian-jira/WEB-INF/classes
-# defaultMode:
-# content: |
-# foo=bar
-# hello=world
+additionalConfigMaps:
+ - name: extra-configmap
+ keys:
+ - fileName: synchrony-args.properties
+ mountPath: /var/atlassian/application-data/confluence
+ defaultMode:
+ content: |
+ hazelcast.kubernetes.service-port=5701
+ cluster.interfaces=10.*.*.*
# - fileName: hello.xml
# mountPath: /opt/atlassian/jira/atlassian-jira/WEB-INF/classes
# content: |This is the unlocking key. There is no way one can pass those properties to synchrony through confluence properties. First property overrides the unfortunate env the chart will set to our chosen port 5801. Now synchrony will bind itself to local 5701 and will query remote hosts on the same port.
Second property is a workaround because confluence synchrony process builder insist on passing the property with value 0.0.0.0 to synchrony which, at least in my tests, then barfs out because of no interface matches this “any” value. I just set the value to 10.*.*.* which should cover the pod’s own ip.
Helm It
Helm template with overrides, check output for obvious errors, then install. On first pod startup you are asked to import the sample data, set admin password, and create a FOO project. I suggest to scale down to 0 right after this and edit the confluence.cfg.xml on the shared-home pvc. There set confluence.cluster.authentication.enabled to false. The setting will be picked up on upscale in next confluence pod. For unknown reasons, the cluster auth does not work in my istio clusters. It was the same for Jira where it had to be disabled by global java property.
Set adrift on Memory Bliss of Foo
A few points that were mildly irritating in this Quest for True Confluence:
Forget documentation. It is outdated, incomplete, sometimes contradicting itself. Well, that is why there is source code. I have not checked Confluence source code because I am still recovering from having read Jira source code years back. Hazelcast source code would be sufficient. Or so I thought and happily went down the wrong alley. Confluence uses hazelcast 3.12 and the (then separate) kubernetes plugin 1.5 but search engines will direct you to current hazelcast 4 which has incorporated the plugin. This together with official hazelcast docker images produces massive confusion about which envs or properties are considered by hazelcast kubernetes. There is the HAZELCAST_KUBERNETES prefix but you commonly find a HZ prefix or other creations. Hazelcast accepts very few global properties and relies on either its xml config or programmatic setting of properties. Which means there is very little one can just set on the command line for testing. At one point I was so fed up with the prop chaos, I considered configmapping a hazelcast xml to finally get this going.
Confluence itself is not any better at it. There are more global properties to set than with hazelcast but one never knows if those properties are considered at all. Example is the confluence.cluster.authentication property which, because of its impact, should be a global OPTS property but is not. It can only be set in cfg.xml. Worse, if you set this prop to false and think you do not need the sister prop with the secret, be ready for strange NPE, which naturally do not tell what the key is where the value is null. Please add this to the cfg.xml.j2 template in the image.
Alright, then there are all the properties prefixed with synchrony which lure you into thinking you can actually configure things for the synchrony jvm. Nope, the best you get is making a recommendation which most of the time the confluence synchrony process builder will happily ignore. Just go straight for synchrony-args.properties.
The chart is actually the best thing in all of this. With the exception of the parts that assume you either have external synchrony or none at all, the chart is fairly sane and offers a lot of additionalSomething fields. The port switch from 5801 to 5701 is unfortunate and so is making that into a container env for hazelcast. Took me quite some time to figure out that either the prop hazelcast.kubernetes.service-port or the env is required for proper discovery operation. In my first tests, synchrony on port 5701 always discovered the confluence on port 5801, found a different cluster name, and then blacklisted the ip. So for clarity’s sake and working discovery, always set the property to the jvm directly. Do not be tempted to set an env because that affects both the confluence hazelcast and the synchrony hazelcast. In short, both HAZELCAST_KUBERNETES envs should be dropped from the chart. Those can be templated as jvm properties just like the others.